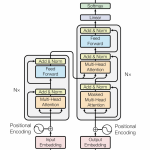
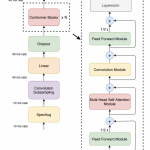
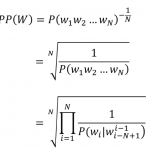ASR之BPE
BPE代表Byte Pairing Encoding,对于英文来说,就是一个或者几个字符的组合。在Kaldi中,word是被表示为,或者分解为phone,怎么做呢?就是根据对应语言的字典模型-lexicon。对于大多数语言,我们都可以采用CMU免费提供的Lexicon。但是对于小语种,那么可能就没有对应的lexicon可以用,那么可以采用BPE。
下面举个例子,假设我们要编码aaabdaaabac,字节对(byte pair)aa出现了最多的次数,我们使用Z(这是因为Z没有在我们的数据中出现)来表示它。这样就变成ZabdZabac。下一个出现出现频次较高的是ab,我们使用Y代替它,现在变成了ZYdZYac。剩下的ac之出现了一次,因此不做处理,不过再扫描一次发现ZY出现了2次,我们使用X代替ZY,整个数据变成XdXac。这就是BPE的算法。在ASR的任务中aaabdaaabac就是我们的训练数据集的所有的text。
在K2的中就用到了BPE,可以看到在librispeech的data下面看到BPE500,BPE1000,BPE5000之类的,这里的500,1000的数字代表了训练集的数据被最多切分成多个word pieces。下面的reference的第二个链接Daniel Povery介绍了BPE。