Kaldi之WFST
WFST是什么
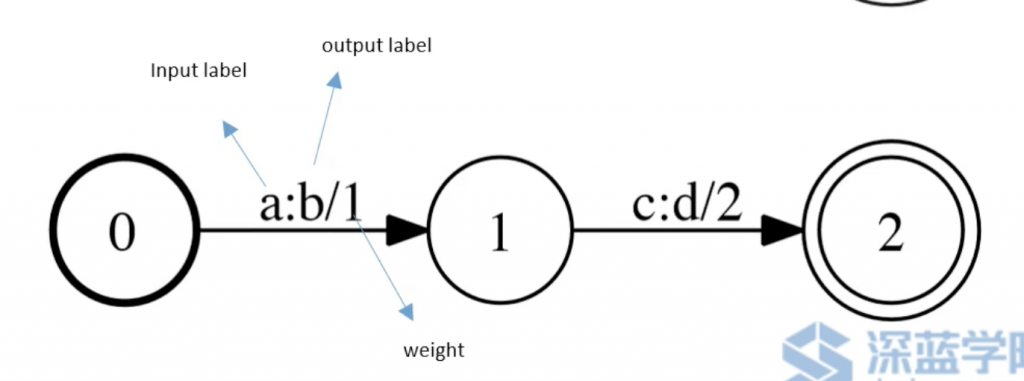
WFST : Weighted Finite State Transducer
FSA : Finite State Acceptor
用来判断一个字符串能不能被接受。
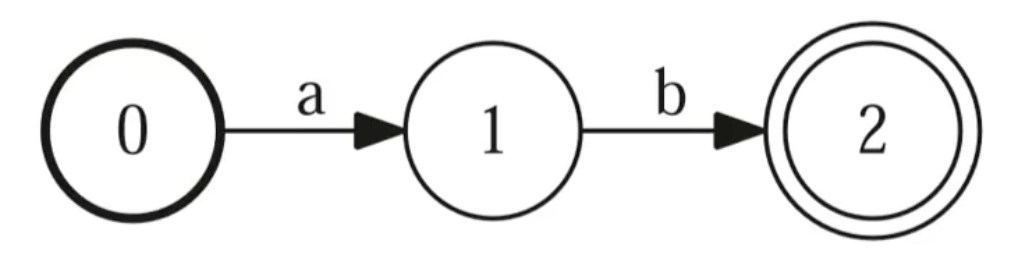
WFSA : Weighted Finite State Acceptor
用来判断一个字符串能不能被接受,并且给出能接受的概率。
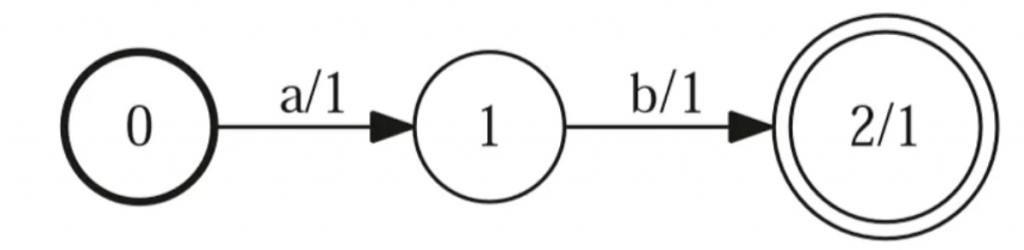
WFST : Weighted Finite State Transducer
用来把一个序列转换为另外一个序列,并且给出转换的概率。它有输入输出,iLabel,oLabel,weight,FSA可以看作iLabel,oLabel是相同的。
WFST的三个基本操作,
Compose
Determine
Minimize
Kaldi使用了OpenFST来实现这3个操作,不过为了效率有自定义的实现。
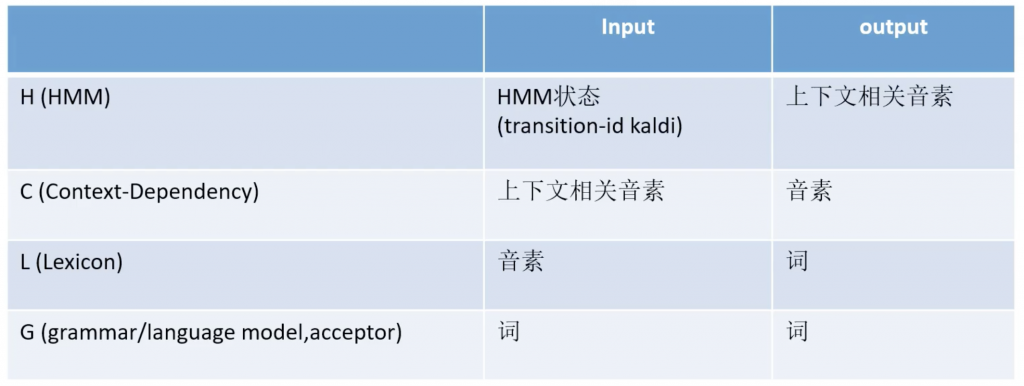
HCLG
HCLG得到一张静态的网(图),解码是输入MFCC,然后使用accostic model – H(就是final.mdl),通过Viterbi解码,Pruning得到HMM的状态,然后放在静态的HCLG走一圈得到最后的word id,通过映射得到text。这里我们省略了Pruning(Beam Search,histogram pruning),生成lattice,recoring的部分。
word和word之间的概率有LM(G.fst)得到,word扩展成音素,音素之间的概率由发音词典-lexicon(L.fst)得到,音素扩展成三音素,它由conext-dependency的C得到,音素扩展成HMM状态,状态之间使用状态转移概率得到。
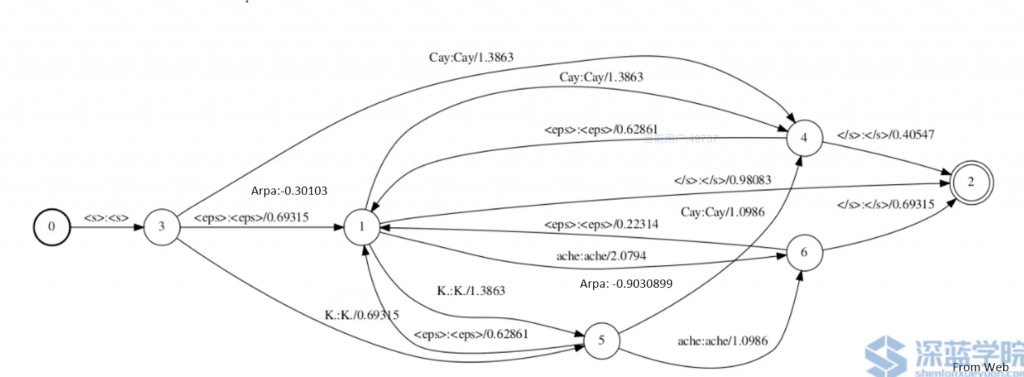
G – Grammer
G.fst
G其实是一个WFSA,因为它的ilabel和olabel是相同的。
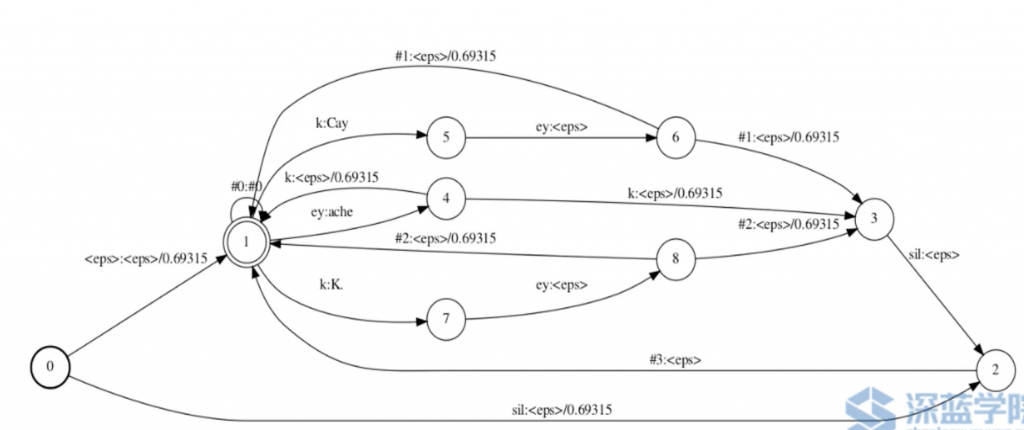
L – Lexicon
L.fst
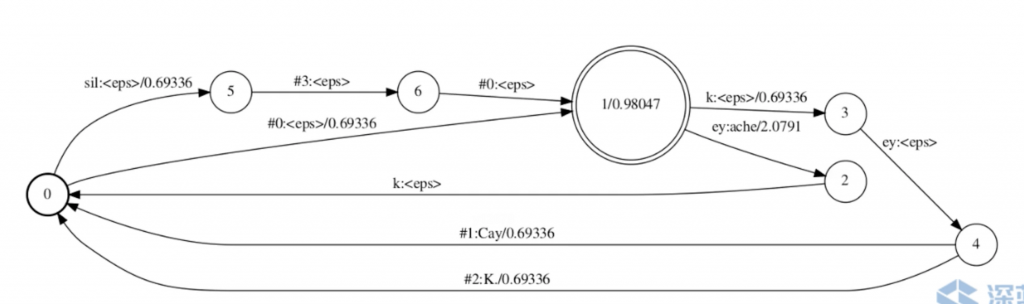
L Compose G
C – Context Dependency
Kaldi并不会生成单独的C.fst,而是动态的生成CLG,使用的命令是fstcomposecontext。是cd-phone通过穷举所有cd-phone所生成的图中,很多都用不到,这样做可以加快处理速度和节省空间。
H – HMM
理论上,只要把pdf-id映射到cd-phone就可以了,但实际上由于Kaldi的决策树中,一个pdf-id可以对应若干个cd-phone,所以引入了
transition-id和transition-state。
transition-id = (transition-state,transition-index)
transition-state = (phone,hmm-state,pdf)
pdf = (forward-pdf,self-loop-pdf)
HCLG
下面是Kaldi中形成HCLG的过程

对于HCLG,每个arc的ilabel是transition-id,olabel是word-id,weight为transition的概率或者LM的概率。