ASR之Self Supervised Learning
2022年8月1号:Self Supervised Learning的框架,参数非常多,比如典型的BERT,参数个数为340M,训练需要的数据量巨大(这个使用类似GigaSpeech或者MultiSpeech可以解决),需要很多GPU,或者需要直接跑在TPU上,训练需要很长的时间才来完成(具体的例子参看本文后面附的视频的44分钟部分)。这里说这个,是为了说明训练BERT based的模型是个问题。
Supervised Learning和Self Supervise Learning
先看一下Supervised Learning
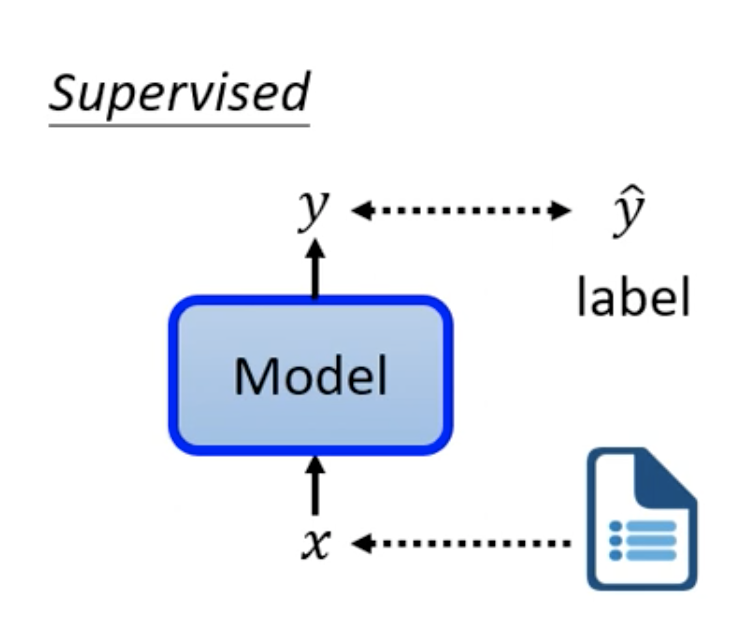
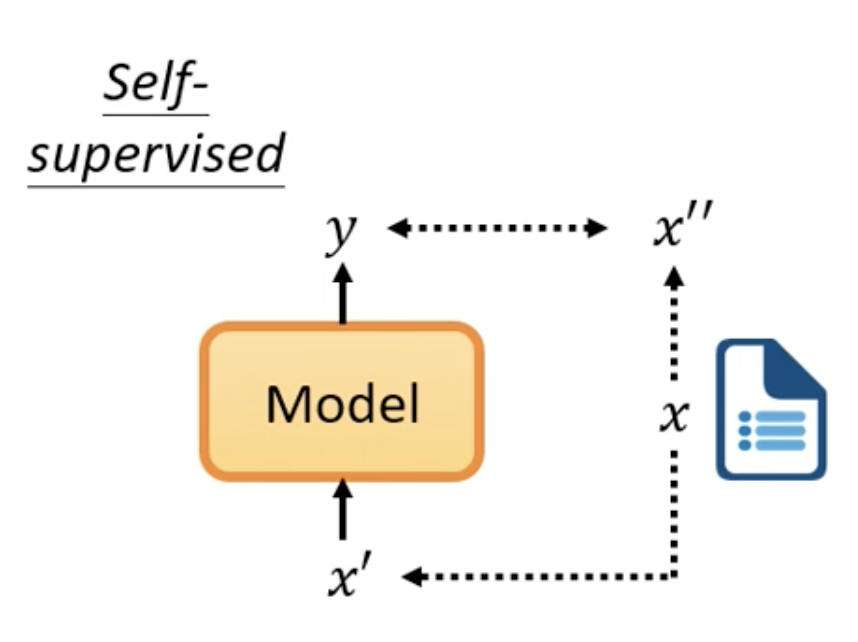
Supervised Learning是有label的,对于输入x我们期望它输出 ŷ。而在Self Supervise Learning,则没有对应的label。
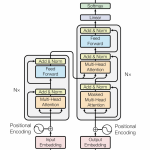
在Self Supervise Learning的领域最出名的就是BERT,下面就以BERT阐述Self Supervise Learning。BERT是为处理NLP而诞生的,它就是Tansformr的Encoder。BERT的网络结构与Transformer的Encoder一摸一样。顺便回忆一下Transformer的Encoder部分,
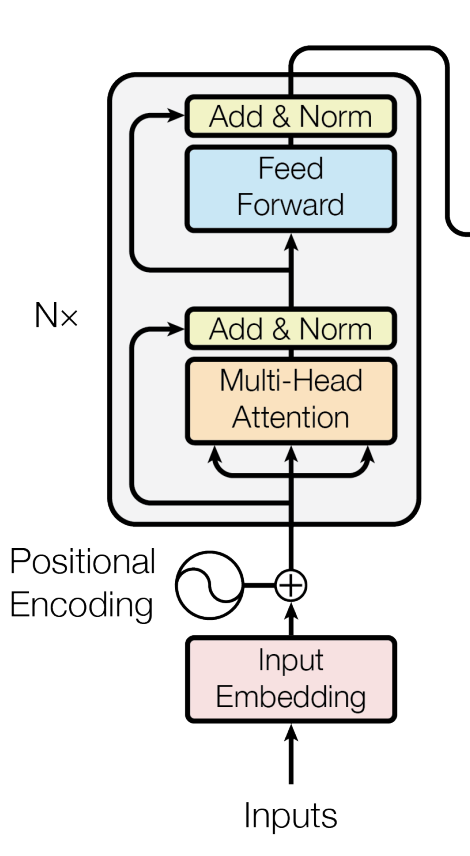
Self Supervise Learning的作用
Self Supervise Learning输出一组向量,它就是输入的一组向量进行编码,得到一组能够表示输入向量的一组向量,或者Self Supervise Learning就是学习如何很好的表达输入。有了这个表达之后,后面可以接具体的应用,比如ASR的任务,将这个表达作为输入,然后做分类任务。从这个意义上说,Self Supervise Learning的模型扮演的角色就是图像分类中的VGG,它是学习通用的图像feature抓取的模型,之后接入自己的小模型,在加上少量数据微调,即可实现自己图像的任务。
在传统的ASR中,feature一般是MFCC,fBank或者PLP,现在我们使用Self Supervise Learning的模型来学习如何更好的拿到一个feature。在ASR的任务中,通常需要所有的数据都是标注过的,这将是一项巨大的任务,使用Self Supervise Learning的模型,我们使用大量的无标注的语音数据(比如去YouTube趴各种新闻,广播,对话等)训练。
上面我们提到feature是Self Supervise Learning的模型最后一层的输出,而研究发现如果把模型每一层的输出加起来作为feature在SUPERB任务上效果会更好(SUPERB会在后面提到)。
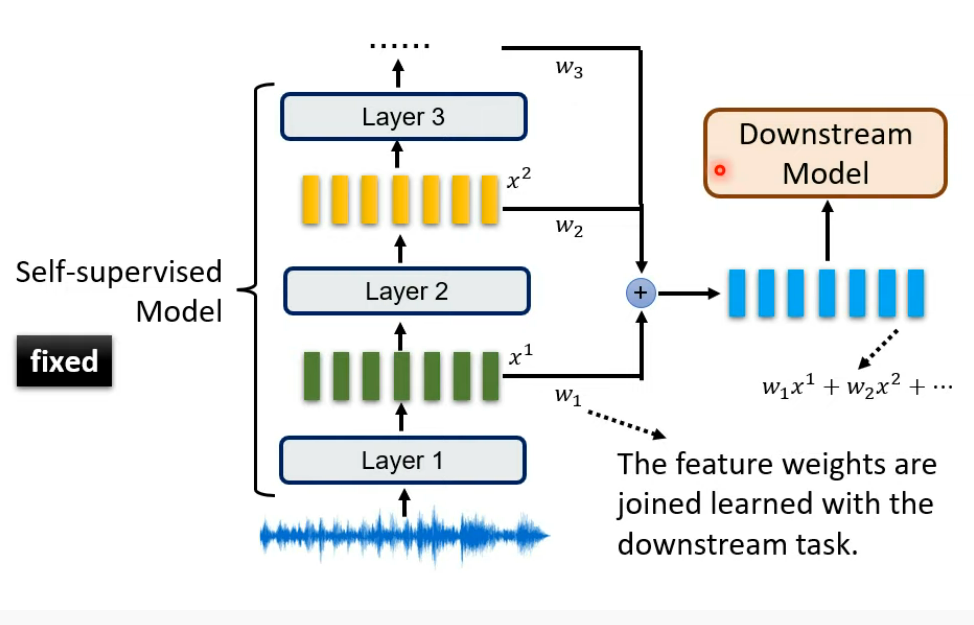
Self Supervise Learning的training
下面说一个BERT怎么自监督学习的,
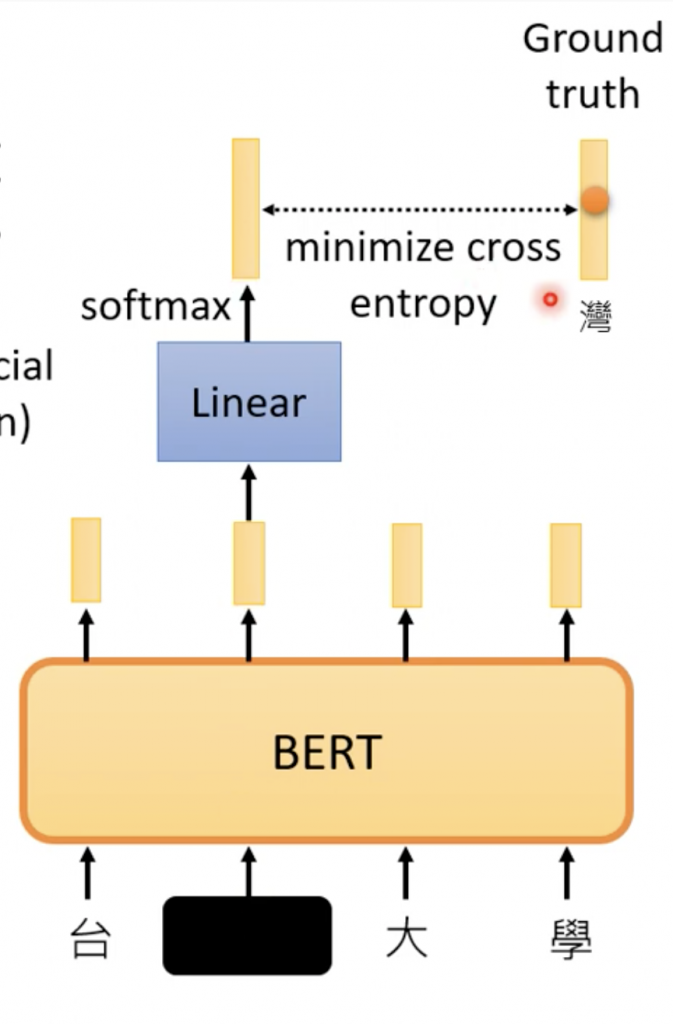
输入台湾大学,4个token,然后随机mask其中的一个token,比如’湾’,把它一个随机的数字,或者定义特殊的符号。然后让它们经过encoder,之后把我们mask的那个向量对应的输出做transform,接softmax得到distribution,就是几率的一维向量,我们期望它在’湾’上的几率最大。
这跟CBOW的技术非常相似,它也是把一个词遮住,让model预测它是什么。CBOW(The Continuous Bag of Words)是用在word embedding上,用来把每一个词表示成一个向量。
注意:BERT,Wav2vec,CBOW,Skip-gram这些模型都是用来产生对向量另外一种表达,这个表达用于下游任务。对于CBOW的简单的介绍可以参看Implementing Deep Learning Methods and Feature Engineering for Text Data: The Continuous Bag of Words (CBOW)
BERT的应用
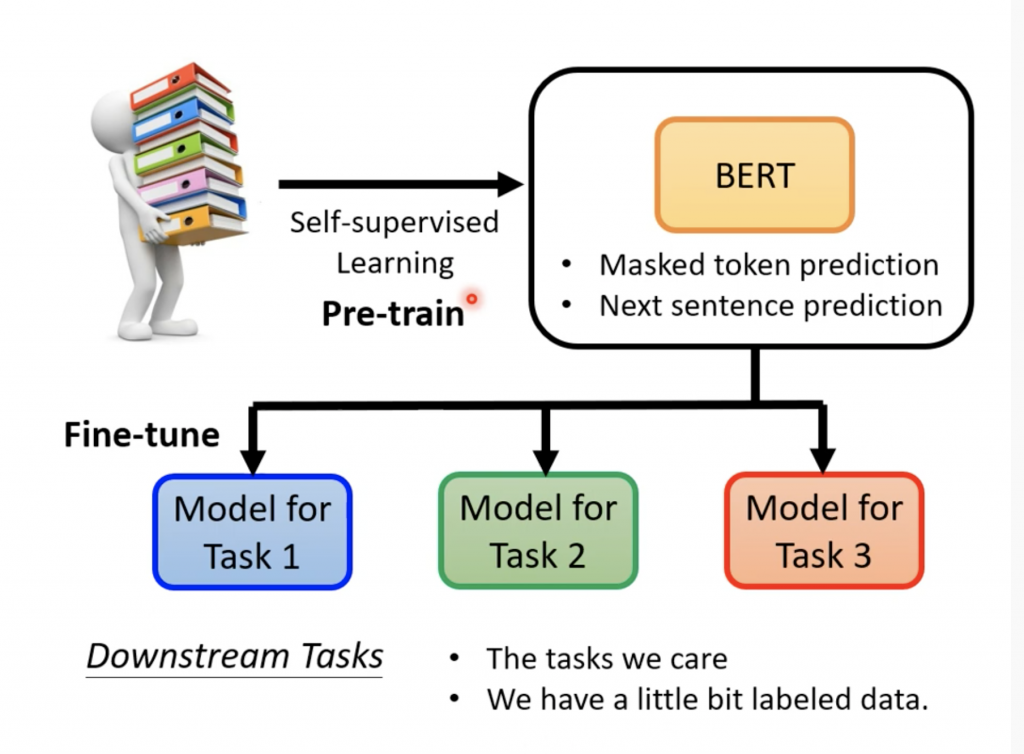
我们可以在BERT上面使用无标签的数据进行训练得到pre-trained的BERT model,之后针对具体的任务,比如ASR,在小数据量的标注过的数据上面fine-tune,就可以得到ASR的系统。
在评估BERT的时候,业界用到GLUE – General Language Understanding Evaluation,它总共9个任务,可以参看
https://mccormickml.com/2019/11/05/GLUE/#:~:text=The%20General%20Language%20Understanding%20Evaluation,The%20collection%20consists%20of%20nine
https://gluebenchmark.com/
语音版的BERT
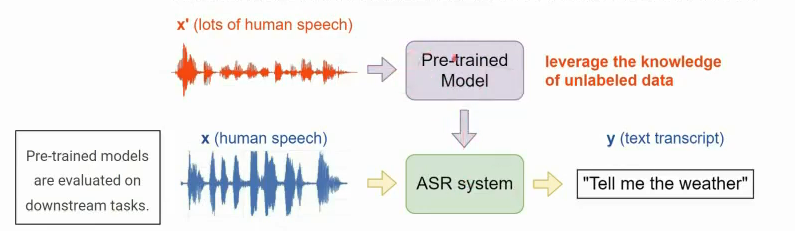
首先基于self supervised learning训练一个pre-trained model,之后使用少量的标注数据进行微调。整个过程可以分为pre-train的第一阶段和微调的第二阶段,第一阶段的也可以称作upstream的model,第二阶段称作downsteam的model。
Train模型的方法
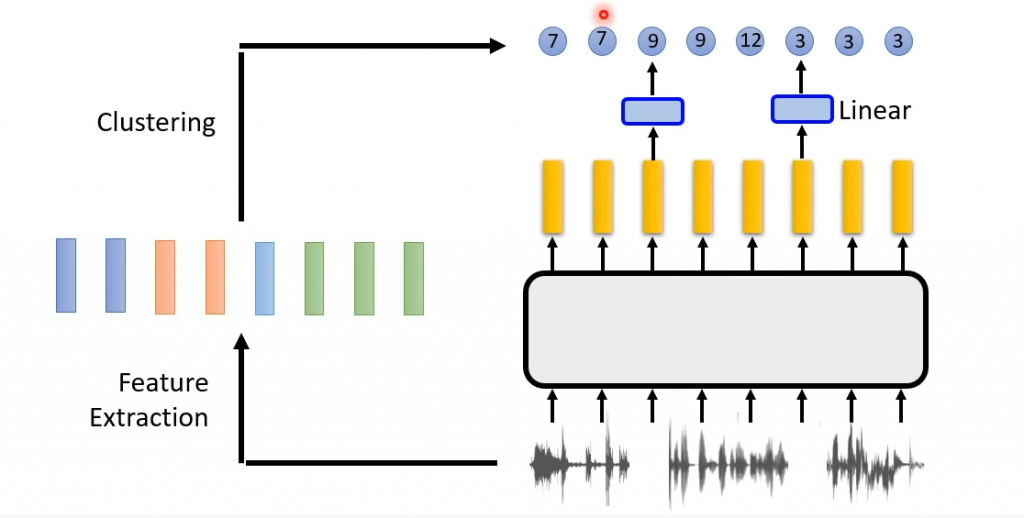
Masking
这里的BERT based的model,在训练的时候,跟上面的BERT的训练略有不同,上面的一段话先mask掉一部分word,然后让model预测。因为ASR中,输入的不是文字,而是语音,采用类似的想法,就是mask掉一组语音帧中连续的几帧,然后重建它们(reconstruction)。因为word它是分散的整数值(vocabulary里面的index值),比如语音帧则是连续的float的数值(无论是MFCC,fBank还是wav data),因此需要一个方法做比较,就是计算loss,这里可以采用reconstruction loss。
为什么不是mask掉一帧,这是因为语音帧的时长就是20ms,再加上重叠10ms,所以如果只是一帧,那么神经网络就可以很容易学到(直接复制前后一帧,或者采用平均值),这样学习出来的网络泛化能力很弱。
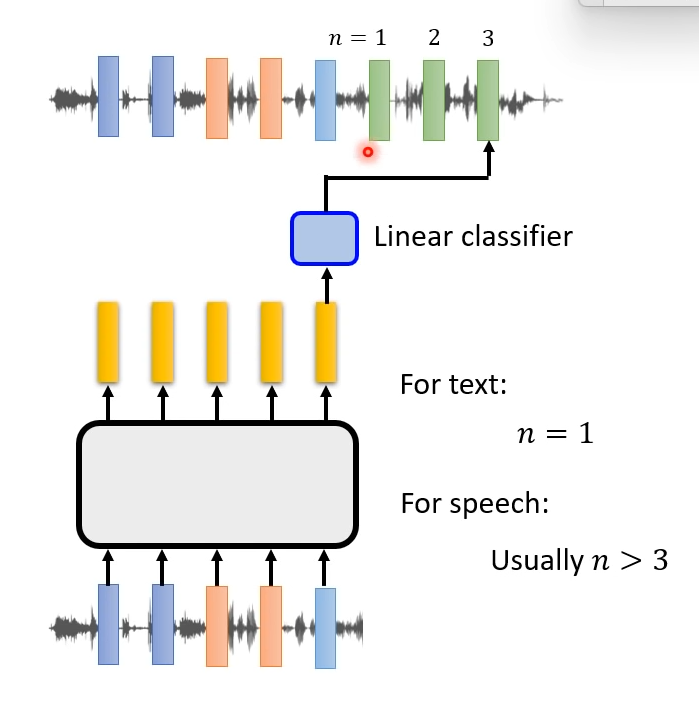
Predictive
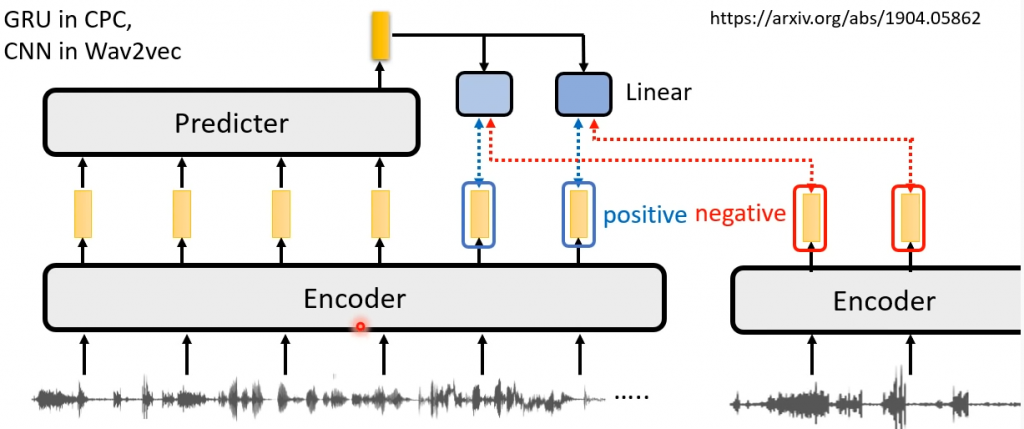
Constractive
Upstream的model
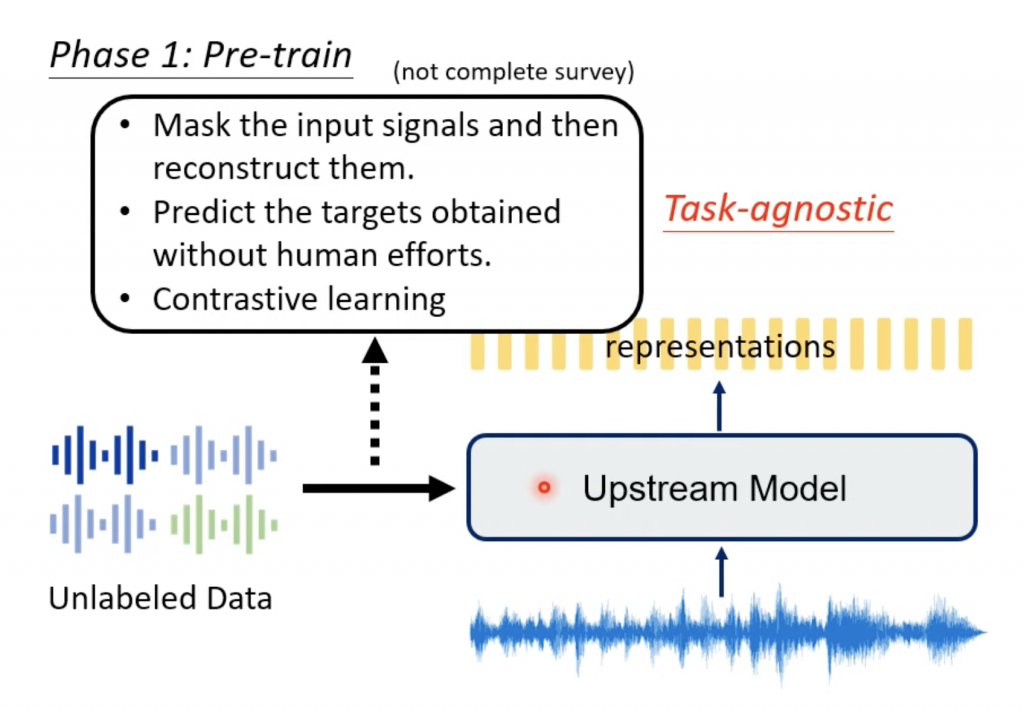
预训练(pre-trained model)的模型
* PASE+
* APC
* NPC
* Mockingjay
* DeCoAR
* Wav2vec
* HuBERT
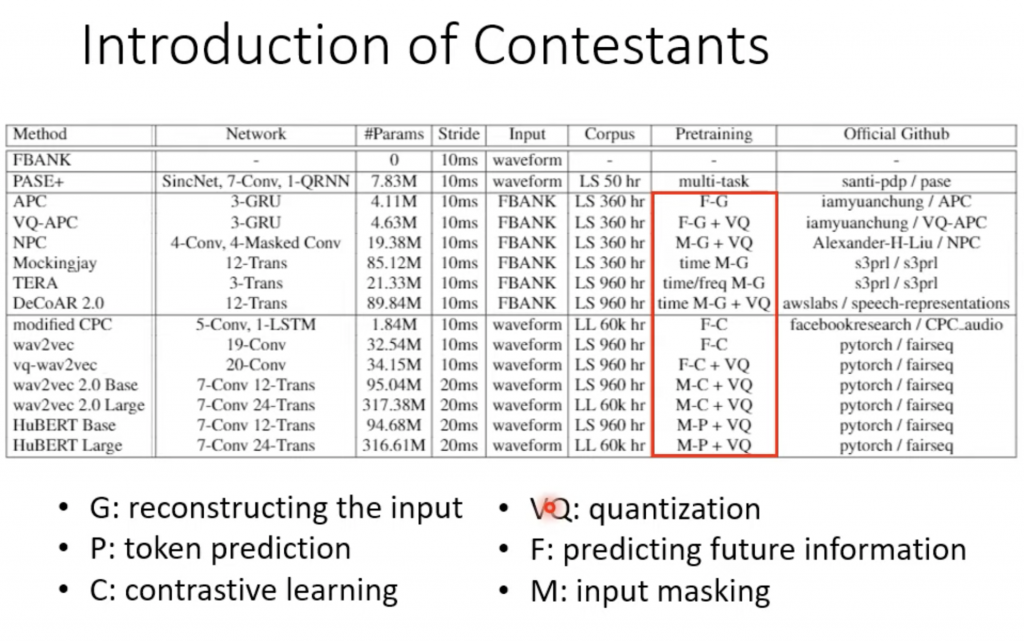
下面是每个模型简单表述
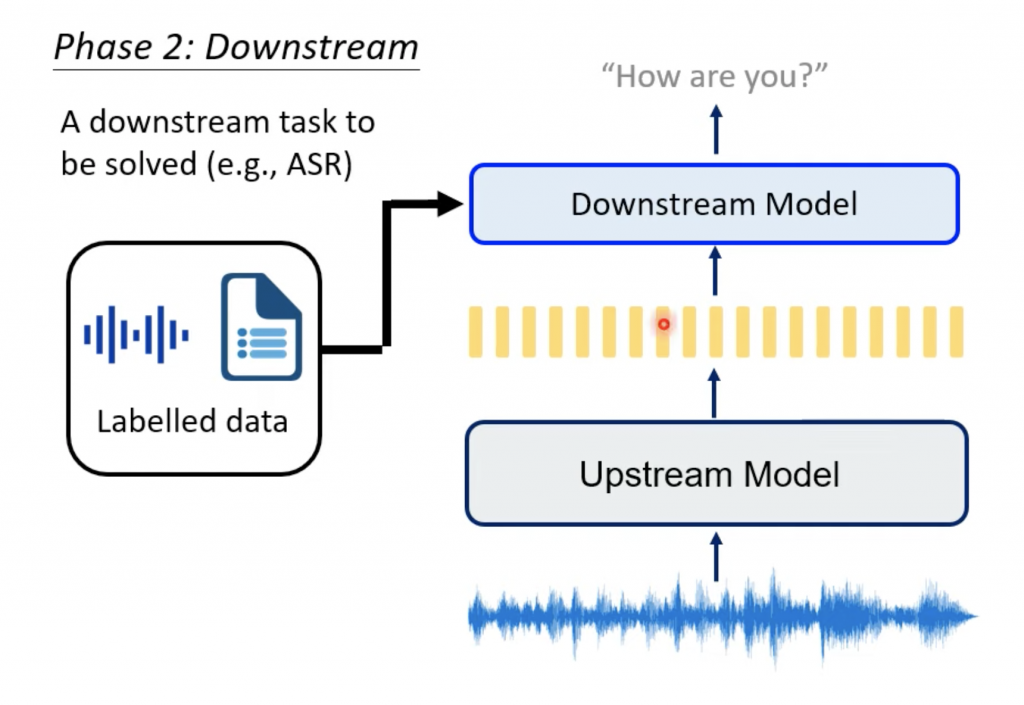
Downstream的模型
Downstream的模型就是具体的应用,比如ASR。
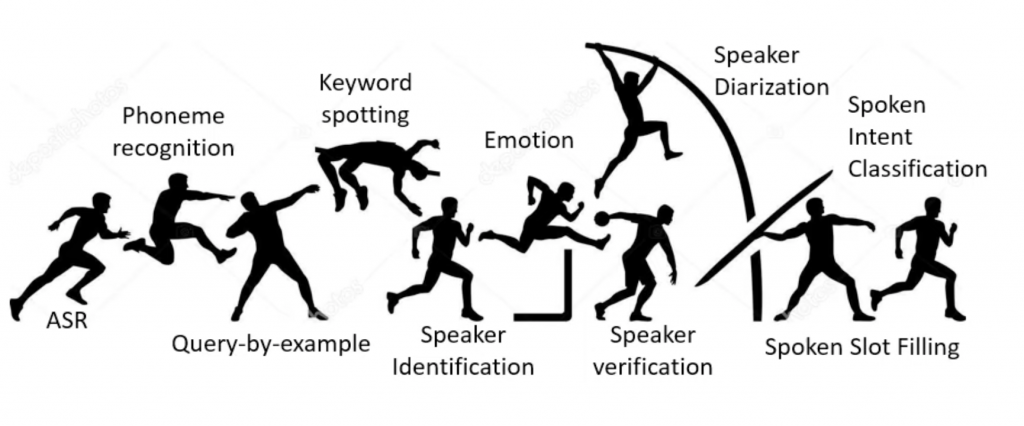
SUPERB
在BERT应用在NLP的任务中,NLP有很多任务,因此有人把BERT得到的feature应用在所有的任务上,然后查看score,这个事情叫做GLUE(General Language Understanding Evaluation ),在语音的研究领域也有类似的东西,叫做SUPERB(Speech processing Universal PERformance Benchmark)。
关于BERT的GBLUE,可以参看GLUE Explained: Understanding BERT Through Benchmarks
下面是SUPERB的所有任务
下面是使用不同的self supervised learning模型在SUPERB上的表现
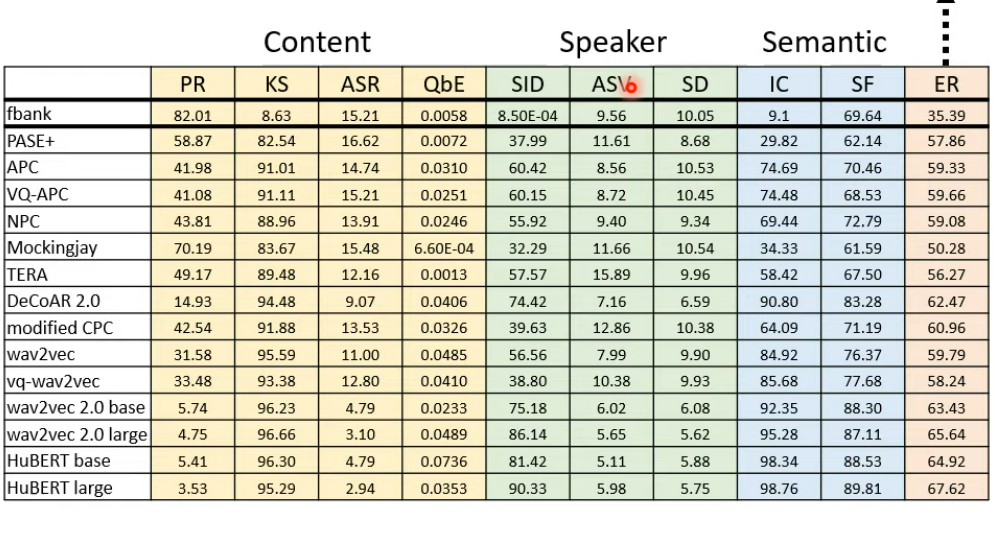
参考
https://towardsdatascience.com/wav2vec-2-0-a-framework-for-self-supervised-learning-of-speech-representations-7d3728688cae
https://paperswithcode.com/sota/speech-recognition-on-librispeech-test-clean
本文的截图来自: