Self Attention和RNN,CNN
Self Attention和CNN,RNN有很多的相似之处。这篇文章大致说一下有什么的相似之处,关于细节需要研读下面提到的相关论文。
Self Attention和CNN
CNN是self attention的子集。

- CNN是self attention的简化版,或者说CNN是受限制的self attention
- self attention的复杂版本的CNN
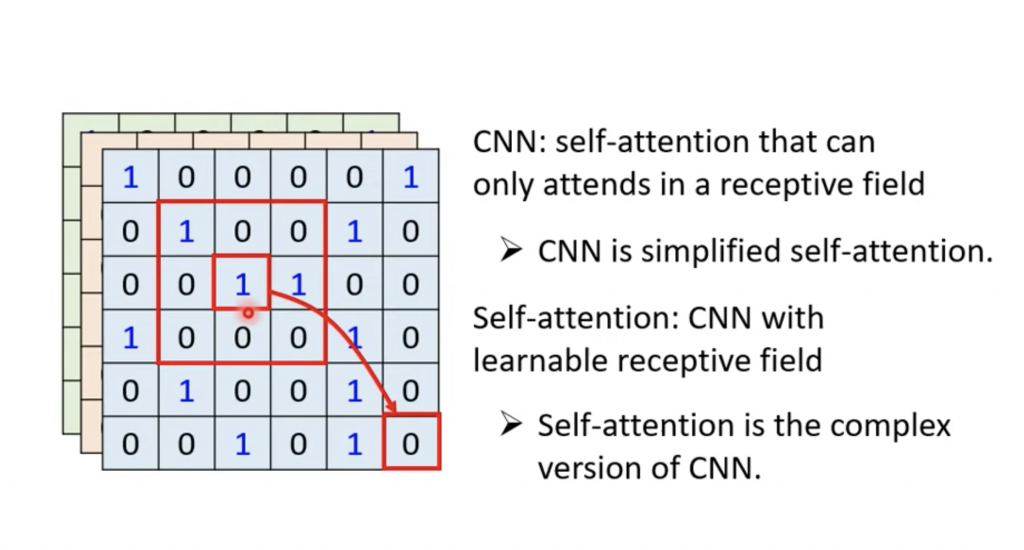
mnist大家一般都是采用CNN,但是我们也可以采用self attention,这个时候我们则是学习图像中的某个像素和图片中的所有像素的关系,而在CNN在是计算某个小范围的像素间的关系(和所选择的卷积核的大小有关系)。
这里可能有个问题,就是好self attention的输入一组的vector,图像是怎么做的self attention的输入呢?答案是图像看成RGB三个通道,每个通道拆分出来,然后每个通道展成一纬的向量即可。
有人从数学的角度详细的阐述他们的相似性,
On the Relationship between Self-Attention and Convolutional Layers
Google在图像识别中用self attention替代CNN,
An Image is Worth 16×16 Words: Transformers for Image Recognition at Scale
下面的实际结果

可以self attention在图像数量达到3亿张的时候,准确率要好过CNN。
Self Attention和RNN
Self Attention也是很相关的,
可以参看这个论文
Transformers are RNNs: Fast Autoregressive Transformers with Linear Attention
下面的对比一下self attention和RNN
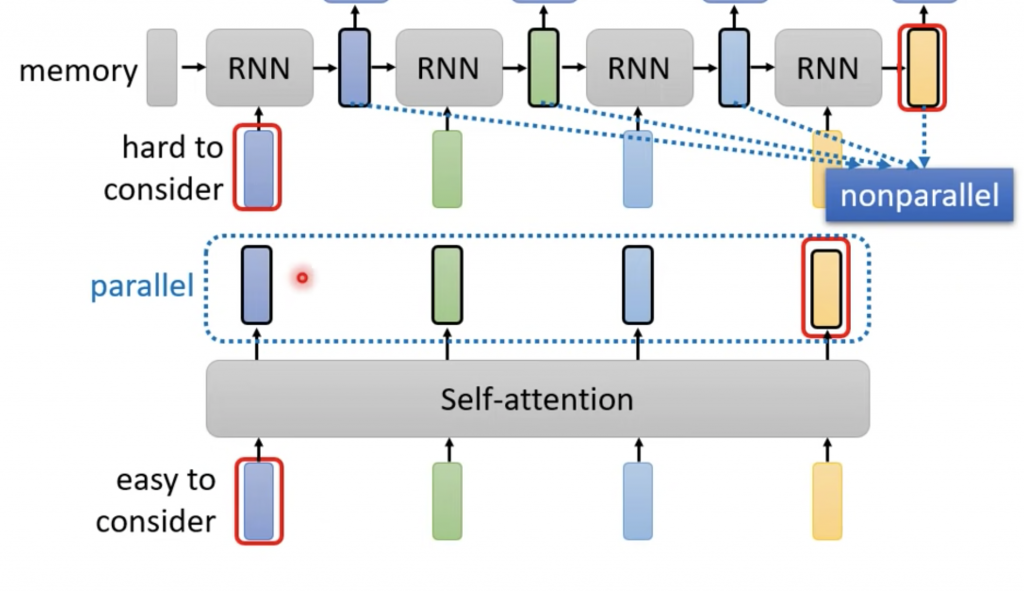
RNN和self attention都是输入一组向量,输出一组向量。RNN是每一个向量的输出会考虑左边的输出,而self attention会考虑所有的向量;如果将上图中RNN采用双向的RNN,虽然每一个输出虽然也会考虑右边的向量的,但是RNN中没有直接考虑输入向量,而是输入经过一些列操作后的向量,self attention则是直接考虑原始的输入。
这里提一点self attention相比于RNN优秀的地方,RNN中每一个输入都要依赖前一个的输出,而self attention没有依赖,所以self attention每一个输出向量可以分开计算,可以做并行计算。
很多deep learning的架构里面含有self attention,在命名的时候大家习惯加上former,我想是因为Google发布self attention是来自那篇文章使用是transformer的缘故,Linformer,Performer,Reformer,以及最近出来的conformer。
Self Attention的问题
使用Self Attention之后我们丢失sequence原有的位置和先后顺序信息,如果最后的输出对位置和先后顺序信息敏感,比如ASR任务,我们可以加一个对位置信息的Encoding,比如在Transformer中Positional Encoding。
本文的图片来自