
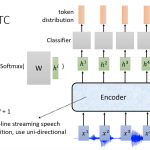
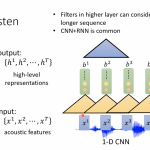
ASR之Self Attention
self attention和Listen Attention Spell笔记中提到的Attention非常相似,不过它作的点乘z不再是有外部提供,而是就是自身,另外多了V向量,在LAS的Attention种V就是向量h自身。
self attention是Google发表的Attention is All you need这篇论文中提到,其实论文主要的说的Transformer,而self attention是它的其中很重要的module。
理解self attention的时候关键查看query,key和value这3个变量。那怎么理解这三个东西呢?
这三个东西的概念来自查询系统,或者说搜索。例如,你在YouTube上面输入要搜索的视频(query),搜索引擎就会把你的query和数据库所有的key(视频名字,描述等)做比对,然后给出最匹配的视频(value)。
下面看一张具体的图来理解query,key和value是什么,怎么操作的,
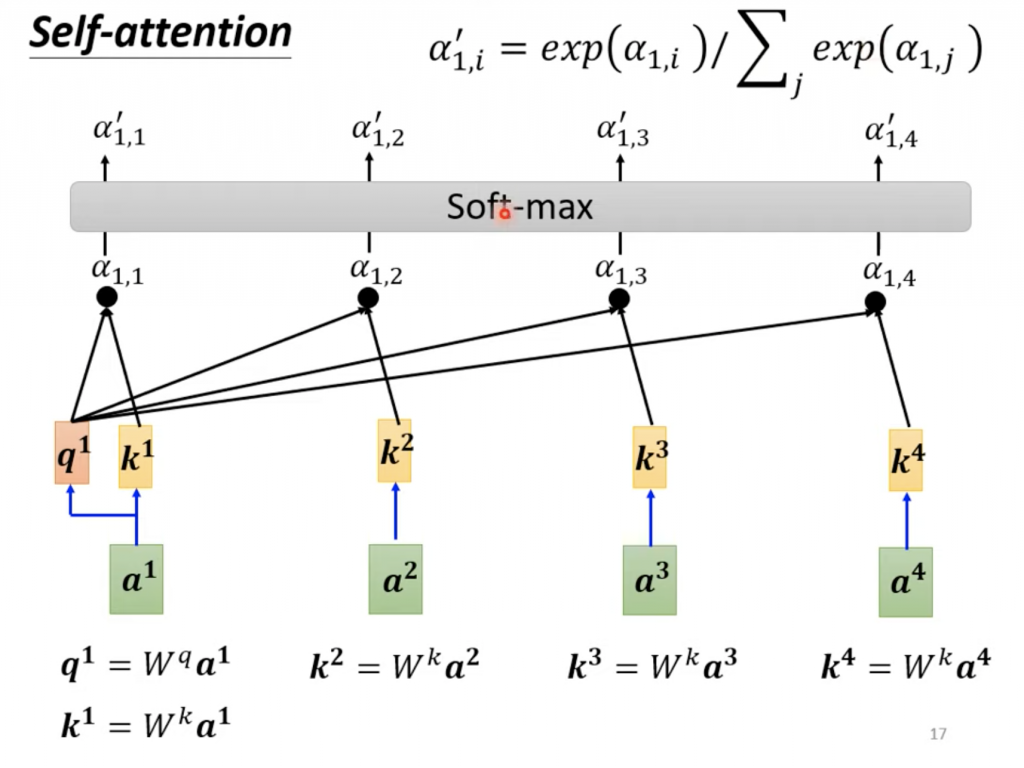
可以看到self attention是将自己作为q,这里的q就是LAS中的Attention的z。图中Wq,Wk,Wv是三个矩阵,是三个参数,需要通过训练得到。q,k,v的计算公式,
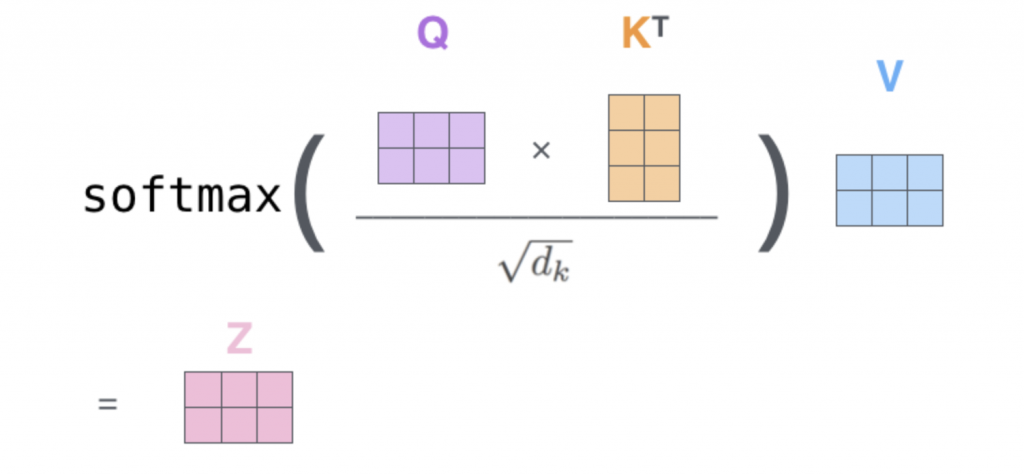
我们放一张在LAS中Attention的计算α的图,
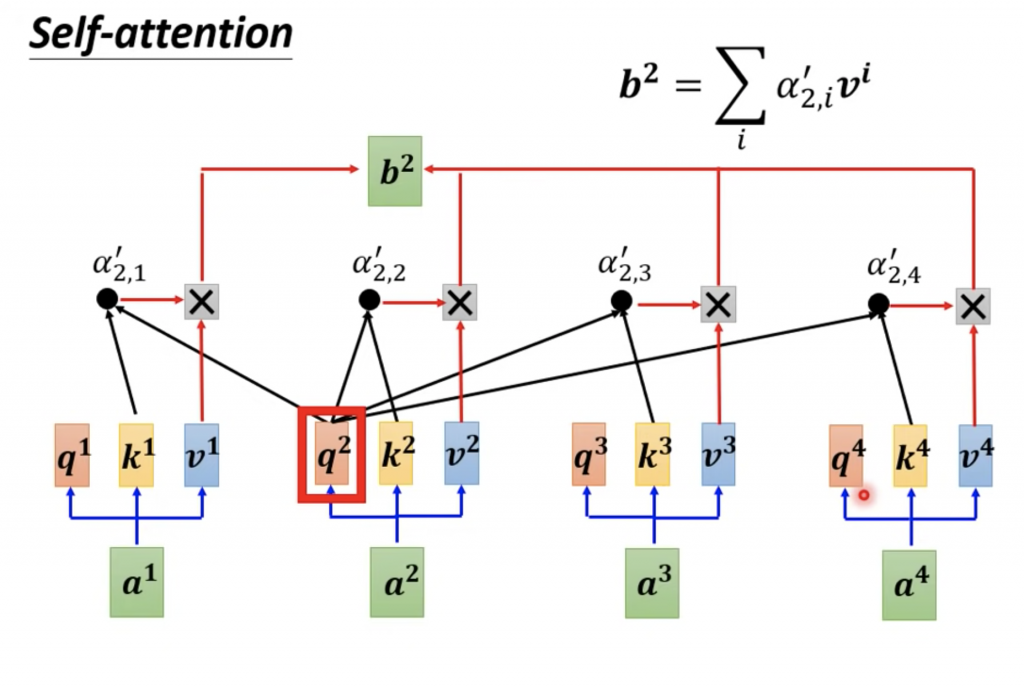
下面时候self-attention的α的计算过程
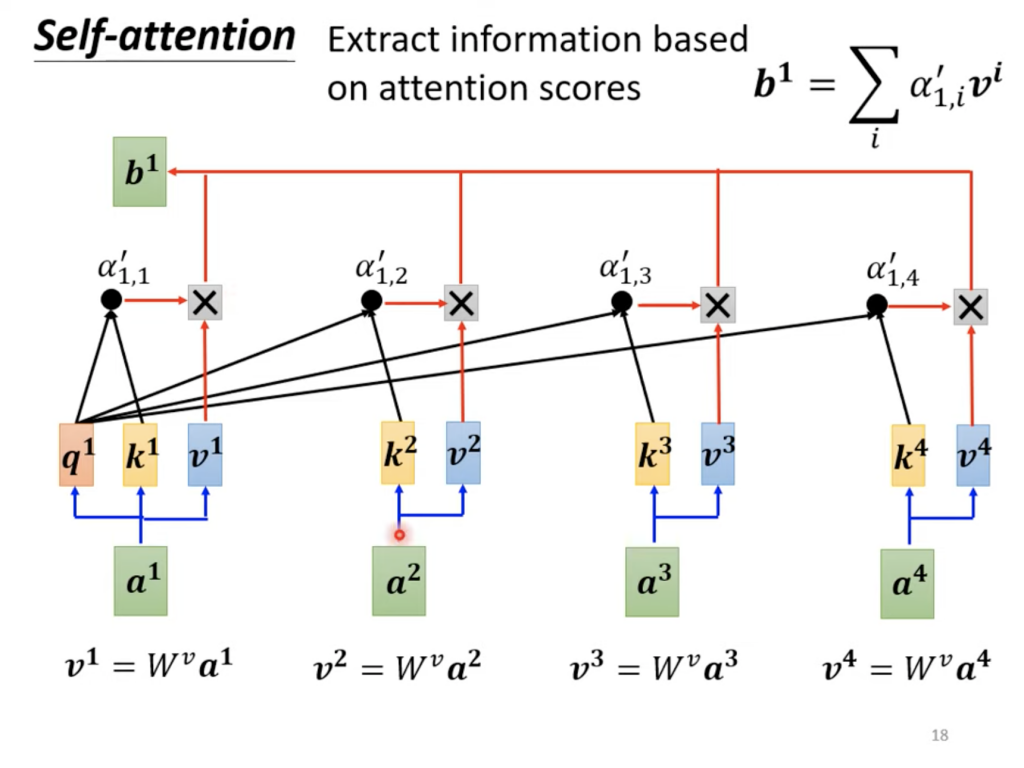
这边多了向量V,在LAS中Attention中得到α后,是乘以h向量,这里是乘以v向量。下面是全部的α的计算过程。
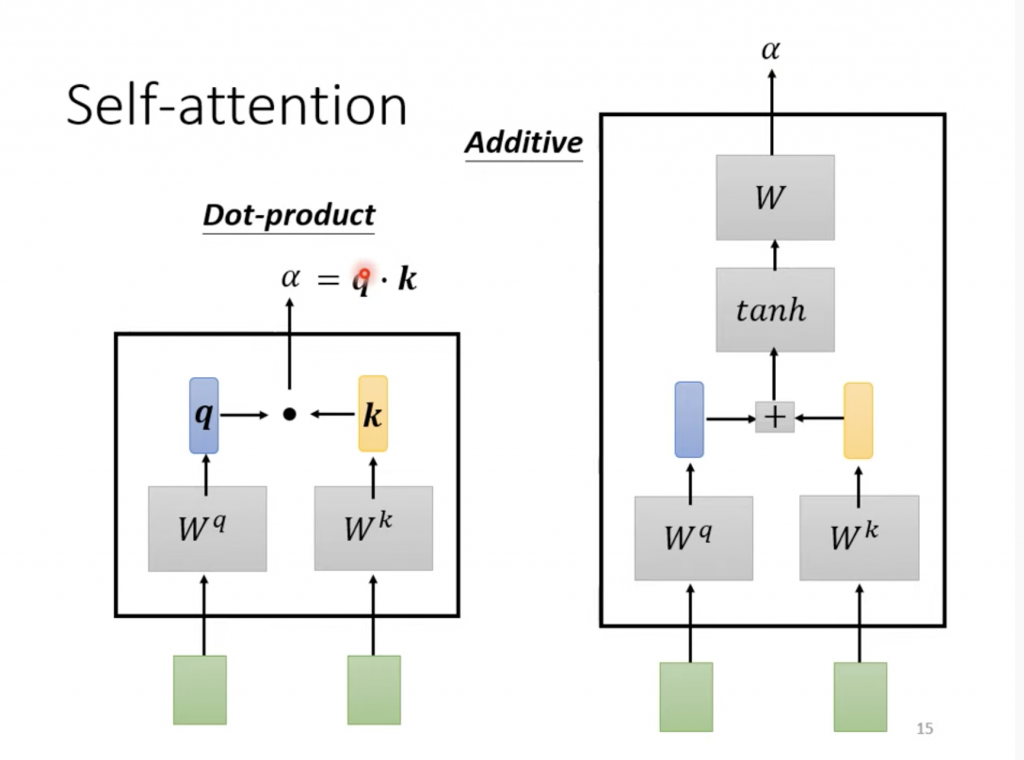
关于α的计算和LAS的Attention一摸一样,也是dot product或者Additive Attention
下面放一张动态的图来表示这一过程
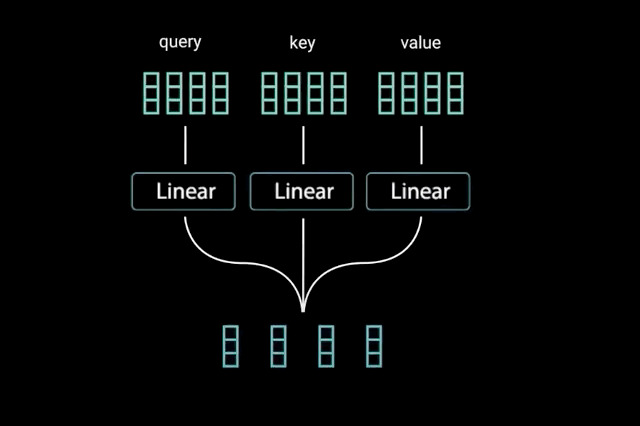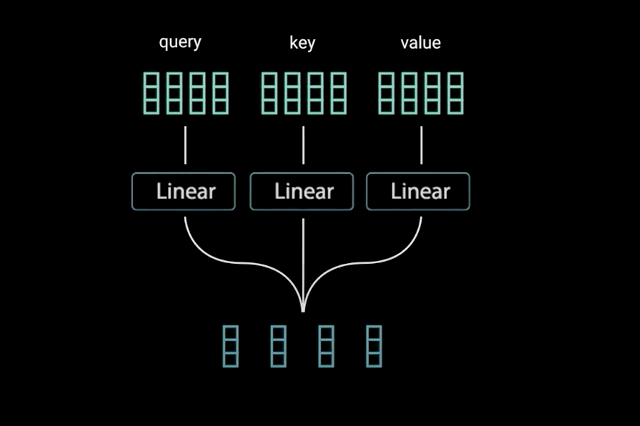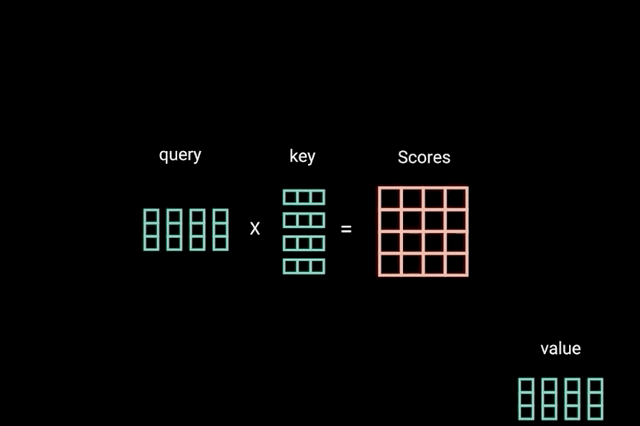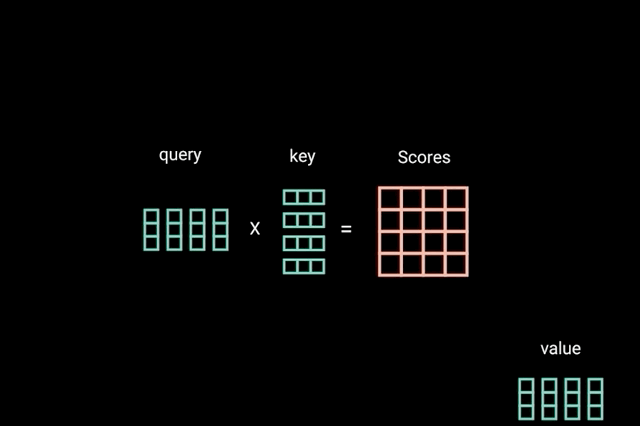
计算完Self Attention之后,使得Attention Score得分比较高的变的更加重要,得分低的更不重要,也就是更加不相关。
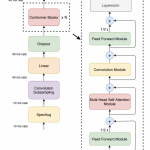
Multi-Head Self Attention
Multi-head self attention就是有多组的q, k, v,分别计算不同的Self Attention,每一个计算Self Attention的部分称作一个头(Head),每个Self Attention计算得到一个vector,然后把这些vector拼接起来,线性变换一次然后作为Multi-Head Attention的输出。 理论上,每一头关注输入序列中不同的东西,从而使Encoder对输入的表达能力更强。
下面给出一张2头的self attention

从输入到q,是乘以Wq矩阵,从q再乘以另外2个矩阵就得到新的qi,1和qi,2。同理可以得到ki,1 ki,2和vi,1 vi,2
接下来的操作就和单头的self attention的计算一样得到不同b,不过这里会得到多个bi,1 bi,2 接下来把bi,1 bi,2拼接起来,乘以一个矩阵就得到self attention的bi.

上面是以2个头举例说明,如果是多个头,q乘以多个矩阵,得到多个qi,n。多个k和v。
这里给出总的Multi-head self attention的图
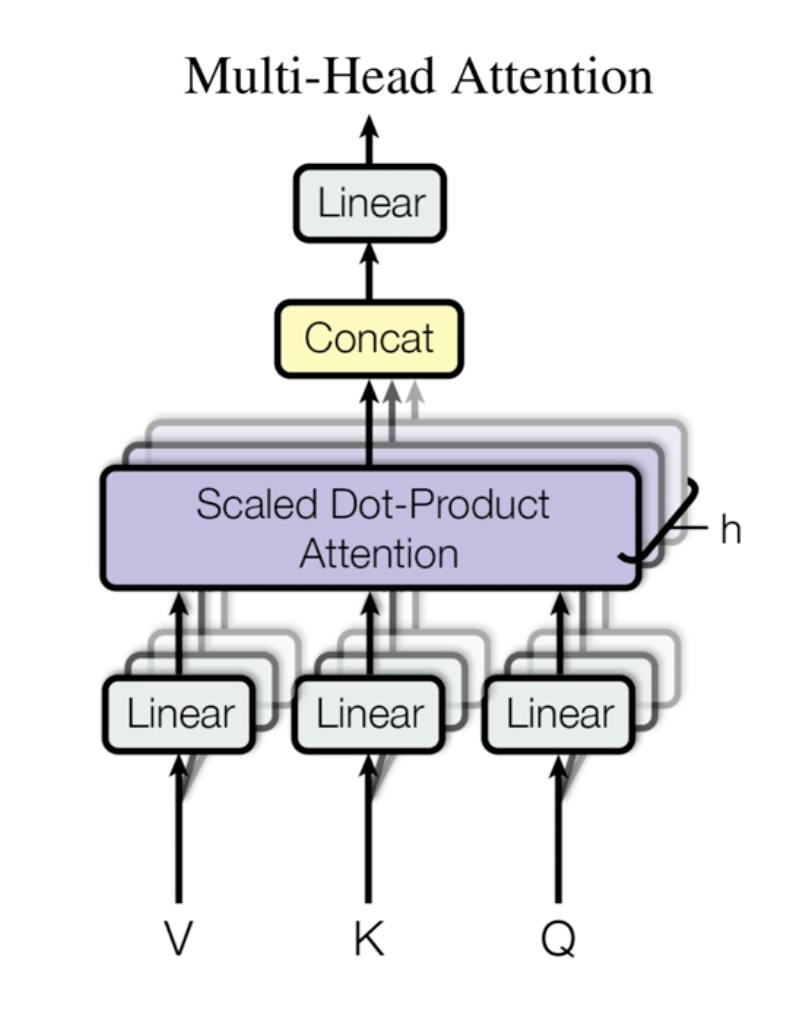
图里面的linear就是乘以矩阵的操作,concat就是上面提到的拼接。
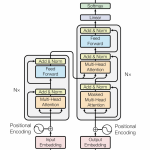
Self Attention的问题
使用Self Attention之后我们丢失sequence原有的位置和先后顺序信息,如果最后的输出对位置和先后顺序信息敏感,比如ASR任务,我们可以加一个对位置信息的Encoding,比如在Transformer中Positional Encoding。
参考
Illustrated Guide to Transformers- Step by Step Explanation
Illustrated: Self-Attention
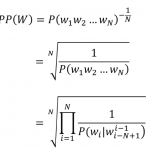
2 Replies to “ASR之Self Attention”