
ASR之声学模型的观测状态
这里的声学模型可以时候GMM-HMM或者DNN-HMM。
在HMM的模型中,我们隐状态和观测状态,比如下面的例子,
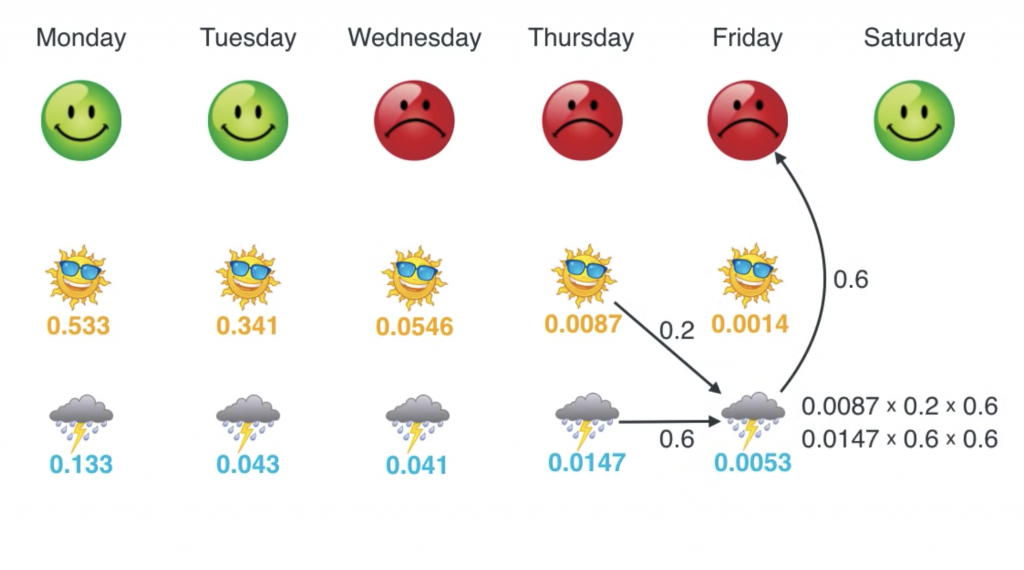
表情为观测,天气为隐状态,我们是在知道表情的情况下,使用viterbi算法去推测天气。
viterbi算法涉及3个概率,初始概率,转移概率,观测概率。上面的例子中就是给定天气的情况,观测到某个心情的概率。所以这里的观测状态很明确,就是心情。
所以输入 一些列的心情,输出是最有可能的天气序列。语音识别的任务中,输入语音数据,这里我们使用mfcc,输出是隐状态,隐状态是音素扩展而成的状态。而对于mfcc不同的人发同一个音不同,即使同一个人在2次发同一音的时候,mfcc也不同,那mfcc显然不能直接作为观测状态在HMM中使用。我们可以这么做,我们定义一组观测,O1, O2, O3, …. On。然后使用GMM对于mfcc进行建模,使得类似的mfcc作为输入得到相同的观测状态。这个过程其实是聚类。
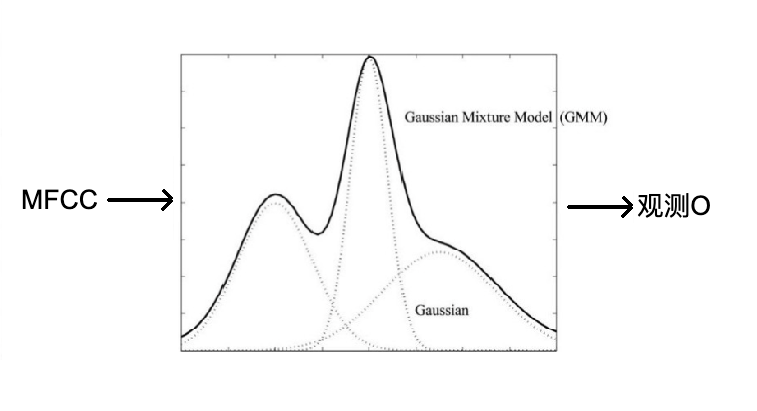
这里有个问题,我们需要定义多少个O,也就是上面的n是多少?(这个问题暂且留在这里)
在HMM-GMM的训练中有个过程是对齐(alignment),就是寻找那些mfcc对应那个观测状态,找到后,将这些mfcc向量代入到GMM中却更新参数(均值,方差,单高斯系数)。
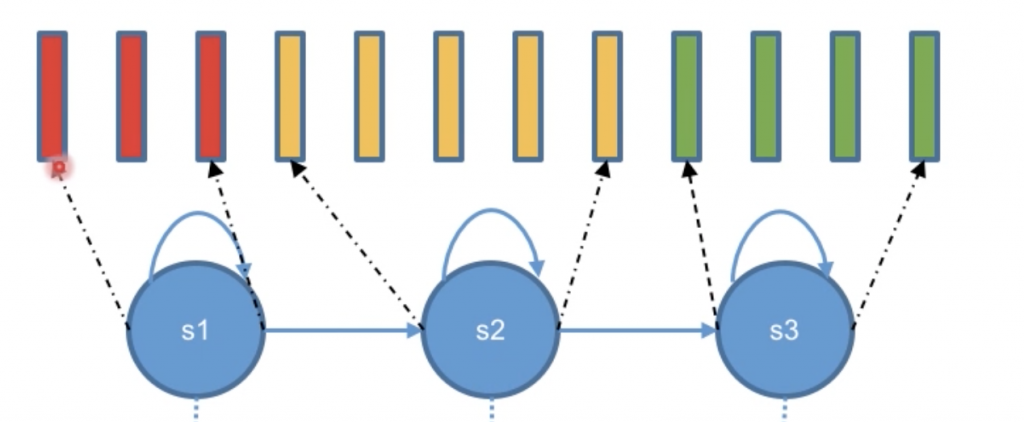
其实这图表达的不够准确,上面的S是隐状态(因为观测状态没有自环-self loop),而实际上,中间还需要画上观测状态O,mfcc也就是上图中小矩形,应该和O直接对应,而不是和S直接对应。

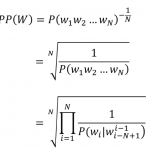
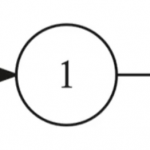
这里的观测是O还是X?
只是个符号而已,你可以用别的符号,比如R,那么在声学模型的公式中也是用R就好。
早起版本的资料中,大家用O比较多,O是Observation(观测)的首字母,后来有人开始用X。